在电商数据分析、竞品监控等场景中,批量获取商品详情数据是高频需求。本文将完整还原一次技术落地过程 —— 从接收客户 “传商品 ID 即得详情” 的需求,到用 Python 实现爬虫核心逻辑,最终封装成可直接调用的 API,为类似需求提供可复用的技术方案。
一、需求拆解:明确核心目标与约束
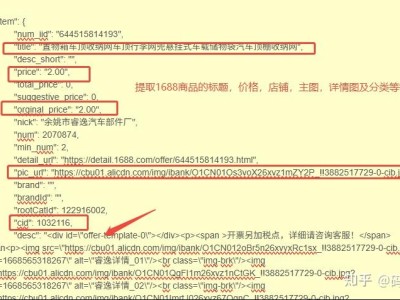
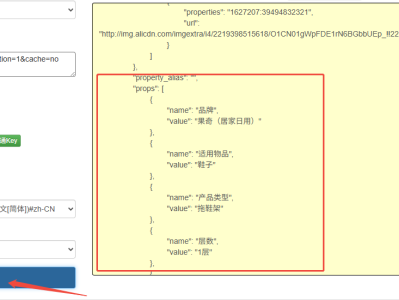
客户是一家电商代运营公司,需要批量获取淘宝商品的标题、价格、库存、规格、详情图等信息,核心诉求有三个:
易用性:无需关心技术细节,仅传入商品 ID(如淘宝商品链接中的
id=123456)即可返回数据;稳定性:避免频繁被反爬拦截,确保批量请求时数据获取成功率;
结构化:返回 JSON 格式数据,方便直接导入 Excel 或接入客户内部系统。
同时需注意淘宝的反爬规则,避免使用高频请求、固定 IP 等易触发拦截的操作,这是技术实现的核心约束。
二、技术选型:轻量且高效的工具组合
针对需求特点,选择 “爬虫 + 后端框架” 的轻量组合,兼顾开发效率与运行稳定性,具体选型如下:
| 技术模块 | 工具 / 框架 | 选型理由 |
|---|---|---|
| 网络请求 | Requests + Playwright | Requests 处理接口请求,Playwright 应对动态渲染页面 |
| 数据解析 | BeautifulSoup + JSON | 解析 HTML 静态内容,直接处理接口返回的 JSON 数据 |
| 后端 API | FastAPI | 高性能、支持自动生成接口文档,开发效率远超 Flask |
| 数据存储(可选) | SQLite | 轻量级文件数据库,无需部署,适合小批量数据缓存 |
| 反爬应对 | 随机 User-Agent + 延时 | 降低请求特征,避免触发淘宝反爬机制 |
三、核心实现:从爬虫到数据结构化
3.1 第一步:分析淘宝商品页面数据来源
淘宝商品详情页分为 “静态渲染” 和 “动态加载” 两部分,直接爬取页面 HTML 会丢失部分数据,需先通过浏览器抓包定位真实数据接口:
打开淘宝商品页(如
https://item.taobao.com/item.htm?id=123456),按 F12 打开 “开发者工具”;切换到 “Network” 标签,刷新页面,筛选 “XHR” 类型请求,查找包含 “item_get”“detail” 等关键词的接口;
分析接口请求参数(如
id为商品 ID)和返回结果,确认该接口包含标题、价格、库存等核心字段(返回格式为 JSON)。
关键提醒:淘宝接口需携带登录后的 Cookie(包含用户身份信息),否则会返回登录拦截页,需提前获取并在请求头中配置。
3.2 第二步:编写爬虫核心代码
核心逻辑分为 “请求数据”“解析数据”“异常处理” 三部分,代码如下(含关键注释):
import requestsimport randomimport timefrom typing import Dict, Optional# 1. 配置请求头(模拟浏览器,避免被识别为爬虫)def get_headers() -> Dict:
user_agents = [ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Firefox/115.0"
] return { "User-Agent": random.choice(user_agents), "Cookie": "你的淘宝登录Cookie(从浏览器复制)", # 需替换为真实Cookie
"Referer": "https://item.taobao.com/"
}# 2. 爬取单个商品详情def crawl_taobao_item(item_id: str) -> Optional[Dict]: # 淘宝商品详情接口(示例,实际需抓包确认最新接口)
url = f"https://h5api.m.taobao.com/h5/mtop.taobao.detail.getdetail/6.0/?id={item_id}"
headers = get_headers()
try: # 加随机延时(1-3秒),降低反爬风险
time.sleep(random.uniform(1, 3))
response = requests.get(url, headers=headers, timeout=10)
response.raise_for_status() # 触发HTTP错误(如403、500)
# 解析JSON数据,提取核心字段(字段名需按实际接口调整)
data = response.json()
item_info = data["data"]["itemInfoModel"]["itemInfo"]
# 结构化返回结果(只保留客户需要的字段)
return { "item_id": item_id, "title": item_info["title"], "price": item_info["price"], "stock": item_info["totalStock"], "sales_count": item_info["sellCount"], "shop_name": data["data"]["sellerInfoModel"]["sellerName"], "detail_images": [img["url"] for img in data["data"]["itemImageModel"]["largeImages"]]
}
except Exception as e: print(f"爬取商品{item_id}失败:{str(e)}")四、API 封装:Python请求示例
# coding:utf-8
""" Compatible for python2.x and python3.x requirement: pip install requests """
from __future__ import print_function
import requests
# 假设 API 封装接口地址 API demo url=o0b.cn/ibrad, wechat id: TaoxiJd-api
# 请求示例 url 默认请求参数已经做URL编码 url = "tb/item_get/?key=<您自己的apiKey>&secret=<您自己的apiSecret>&num_iid=12345"
headers = { "Accept-Encoding": "gzip", "Connection": "close" } if __name__ == "__main__": r = requests.get(url, headers=headers) json_obj = r.json()
print(json_obj)五、落地优化:稳定性与可维护性提升
反爬策略升级:若频繁被拦截,可增加 “IP 代理池”(如使用阿布云、芝麻代理),替换固定 IP;
接口监控:添加日志记录(如用 loguru),记录请求成功 / 失败次数,方便排查问题;
批量请求支持:新增
/taobao/item/batch_detail接口,支持传入多个商品 ID(如{"item_ids": ["123", "456"]}),批量返回数据;Cookie 自动更新:通过 Playwright 模拟登录,定期自动更新 Cookie,避免手动替换的麻烦。
总结
从客户需求到 API 落地,核心是 “以易用性为目标,以稳定性为基础”。通过 “爬虫逻辑模块化 + FastAPI 轻量封装”,既解决了淘宝反爬与数据结构化问题,又让客户无需关心技术细节,仅通过商品 ID 即可快速获取数据。这种方案不仅可复用于淘宝,稍作调整后也适用于京东、拼多多等其他电商平台的商品数据爬取。